Hi Guys,
Welcome back!
In one of the last posts we talked about Table Spool.
We had explained what Spool are for by telling the somewhat curious story of the halloween problem.
Here we specifically talked about a type of spool called Eager Spool
You can look to the execution plan below where the eager Spool is used to avoid the halloween problem in classic query of the "salary increase".. i suggest
Well, if the story of the eager spool intrigued you, today instead we will speak about another type of Spool, the Lazy Spool.
The Lazy spool
Let's take a small step back.
So, what is a Spool operation?
As we have already understood a spool operation is simply a temporary storage of data. Data are read from a source table and stored inside a worktable in the Tempdb database.
While an Eager Spool is used to prevent the Halloween problem, the Lazy Spool is instead used to store data that will later be needed again when running a query.
So, when a Lazy spool is used?
It's certainly a good question ... I know I know..
A lazy spool operation is used when the optimizer evaluate that for the Query is more efficient read data from a worktable than perform multiple access to a table or to an index. Data store in a worktable are reusable.
The types of queries that can benefit from this are, for example, queries with a subquery in the where clause.
Queries where the same data is read more than once can also be a good candidate for a lazy spool.
Remember that Lazy spool operation loads data only where the data is requested.
OK, let's understand it better with an example!
The example
For our example we use the Employee table defined
here
In this simple table we have a list of employees with their salary:
We have a clustered index on the ID field and a non-clustered index on the salary field.
We now write a query in which in the where there is a sub-query.
For example, we are looking for all employees whose wages are below average.
SELECT fr.NAME, fr.salary
FROM EMPLOYEE fr
WHERE fr.salary < ( SELECT AVG(fr2.salary)
FROM EMPLOYEE fr2
WHERE fr2.NAME = fr.NAME )
We run the query and observe its execution plan:
Lazy spool is used not once but three times!
Why?
Before answering to the question let's see how the Query step by step is performed.
P.S. The following description is very important and I advise you to understand it as well as possible ... I will try to write as clearly as possible. So tell me if it isn't!
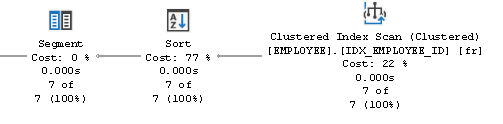
First of all the clustered index scan operator read all the rows of the table employee.
Then the output of this operator is passed to the sort operator.
The Sort operator is used in combination of the segment operator to divide data in many group.
In this case the sort operator sort the data by the "name" field.
Doing in this way the Segment operator can easily divide data in groups where each group has a different name value.
Looking at our data we will have only one group where the name field is 'LUKE'
The output of the segment operator is passed to the Lazy Spool operator.
This Spool operator is called "Lazy" because it creates a temporary table on the tempdb database only when it's needed ... and so right now.
In this case the Lazy Spool will read and store only the data where name is equal to LUKE.
Now all the data store in the temporary table has passed to the nested loop operator:
Now let's look at the rest of the execution plan ...
the one related to the subquery:
We can see that the execution plan starts just by reading the data from the worktable through the (second) lazy spool operator (the one furthest to the right in the image)
Very Very important: At this time the data in the worktable are those that refer to the data where the value of the field NAM is equal to "LUKE"
Data are then passed to the stream aggregate operator that groups data by the NAME field and calculates the average value.
Finally the computed value is sended to a nested loop operator togheter with another copy of the data read from the (third) lazy operator further down the image.
I really hope I was clear!
Blocking and non-blocking operators:
For the sake of completeness, it must be said that the Lazy Spool operator is called non-blocking because, as we have seen, it returns the data during its execution (here group by group .. that is "name" by "name).
The eagle spool operator, on the other hand, is a blocking operator: it reads all the data and returns it only when it has finished.
Finally, a final consideration that we can draw from reading the execution plan:
The execution time is proportional to the number of groups (ie the values of the "name" field)
The most expensive operation is that of sorting the data which alone absorbs 77% of the cost of the maintenance plan.
We'll come back to that later ... maybe looking at the remaining spool operators.
We've surpassed over 6,000 friends on Linkedin!!!!!! ... thank you! I am very proud of it!
Advertising is not bad: if you are really interested in a product (and i select only the themed adv ..), one click is a good idea! ..this will also help this blog.
That's all for today mates!! That's all!!